
vSphereにおけるNICチーミング ガイド(上級編)
本記事では、vSphere ESXiで構成可能なNICチーミングの負荷分散ポリシーについて、Deep Diveした内容をお届けします。
なお、本記事は次の原文記事を翻訳したものがベースとなります。
https://vmiss.net/2019/02/22/vmware-nic-teaming-advanced/
本記事の著者でありますvmiss氏の許可のもと、今回も原文翻訳を行っております。
I got approved to translate her article by vmiss on twitter, thanks a lot your kindness.
※一部私自身が独自に追加した情報もあります。
vSphereの環境において、NICチーミングのためのポリシーは全5種類が存在します。全5種類の名称及び概要は以下のリンクよりご確認ください。
ESXi および ESX における NIC チーミング (1004088)
本記事では、5つの中から次の2つのポリシーをピックアップをして詳細レベルでの説明を行います。
- IP ハッシュに基づいたルート
- 発信元 MAC ハッシュに基づいたルート
5種類の中からこれら2つをピックアップしているのは、他の3つのポリシーと比べてやや負荷分散の手法が複雑だからです。正しく動きを理解する事で、環境に対して最適なチーミングポリシーが選べるようになることを、本記事では目的としています。
IPハッシュに基づいたルート
IPハッシュに基づいたルートの前提条件
まず、このポリシーを利用する場合、ESXiホストが接続されるスイッチに対しLink Aggregation設定が必要となります。(他のポリシーでは、スイッチ側の設定は不要です)
標準スイッチユーザーは、静的LAGを構成する必要があります。
分散スイッチユーザーは、動的LAGを構成する事が出来ます。
スイッチ側の設定も必要ですので、ご利用のベンダーで定義されているLAG設定をスイッチに対して行いましょう。もしあなた自身がこうした設定に不慣れな場合は、次のKBは参考として役に立つといえます。
ESXi/ESX および Cisco/HP スイッチによる EtherChannel/リンク集約コントロール プロトコル (LACP) のサンプル構成 (1004048)
負荷分散手法について
次に図を用いて、ポリシーの動きを見ていきましょう。
![]()
このポリシーでは、トラフィックの送信元と送信先の2つのIPアドレスの情報をベースに負荷分散を行います。
特に各IPアドレスの第4オクテットの数字を2つ取得し、XOR演算にて処理後、更にモジュロ演算によって処理を行います。その結果から得られた数値を基に、このIPアドレスペア(送信元と送信先)に対して特定の物理NICをアサインします。
上図ではXOR演算後、モジュロ演算も実施し、その結果”2”という数字が得られたため、トラフィックがvmnic2から送信されている様子を表現したものとなります。
XOR演算やモジュロ演算についてはコンピューターサイエンスの学習経験がある方はわかると思いますが、興味があって内容を知りたいという方は各用語に対しWikipediaのリンクを張っていますのでアクセスしてみてください。
利点と考慮事項
このポリシーの利点は、IPアドレス毎に利用する物理NICアダプターが異なるため、物理リソースを最大限に利用出来るという点です。
このポリシーの考慮事項は、トラフィックの都度演算処理が発生し、これがホストに対してのオーバーヘッド処理になると言える点です。特に最近では単一のホストが保有する仮想マシン数は年々増えており、仮想マシンが増えるという事はトラフィックも増えるため、本番環境にて運用を行う前には、必ず本ポリシーを利用して問題ないかをテストをする必要があると言えます。
実際に計算をやってみた(IPハッシュ編)
理数科目が大変苦手な私ですが、実際にXOR演算とモジュロ演算により、アップリンク計算を行ってみました。今回は2つのケースを想定してみました。NFSストレージとの通信トラフィックを負荷分散してみるというシナリオです。
XOR演算を行うに当たり今回は次のページを使いました。
https://keisan.casio.jp/exec/system/1311553754
本ポリシーでは、送信元と送信先の第4オクテットの値をXOR演算で計算します。各図内には既にXOR演算後の値が各図の右上に掲載致しました。
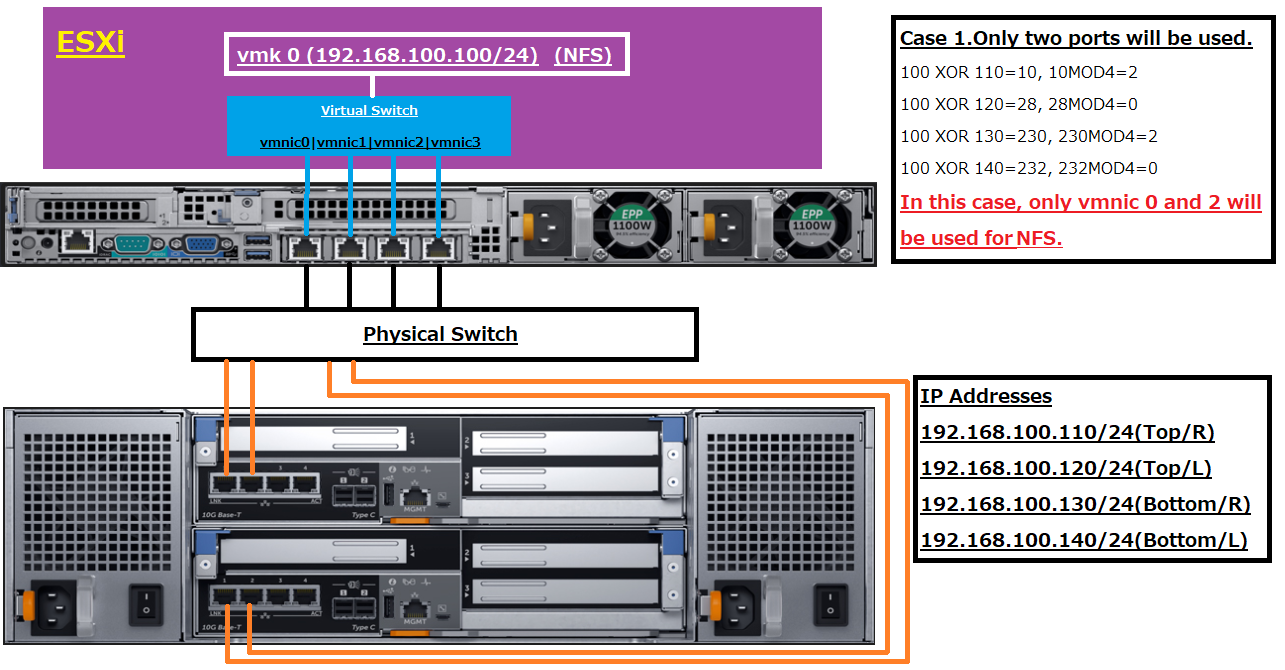
例えばIPアドレス192.168.100.100から192.168.100.110のトラフィック場合は、100XOR110となり、この値は10となります。
この10という値を、今度はモジュロ演算で再計算を行います。今回は物理アダプターが4つある仮想スイッチですので、10MOD4という式になります。この解は2となります。
(10÷4=8あまり2です、このあまりの値である2が解です)この2という値により、トラフィック通過にはvmnic2が使われる、という形でこのポリシーは働きます。
以降他のIPアドレスに対する計算解は図内掲載の値をご覧ください。ここで取り上げましたIPアドレッシングでは、結果的にせっかく4つの物理アダプターが存在するにも関わらず、2つのアダプターしか使われない結果となります。
ではどうすればよいか?ストレージ側のIPアドレッシングを連番にすればOKです。
こうすることで4つの物理NICポート全てがNFSトラフィックで使われるようになります。
なお、今回ご紹介しましたXOR演算やその後のモジュロ演算などについては公式にはこちらのページに掲載があります。IP ハッシュに基づいたルート – VMware Docs
発信元MACハッシュに基づいたルート
次に紹介するのは発信元MACハッシュに基づいたルートです。IPハッシュに比べれば比較的簡単なポリシーです(筆者vmiss氏談)
IPハッシュの場合と似ており、本負荷分散方式でもトラフィック毎に計算を行います。一方でIPハッシュと異なりスイッチ側での設定は不要となります。
負荷分散手法について
本負荷分散方式では、仮想マシンの仮想MACアドレスと物理NICアダプターの数を用いてモジュロ演算を行い、物理アダプターを選定します。IPハッシュの負荷分散の際に、物理NICアダプターの数と、XOR演算後の値をMOD計算し、その値でアップリンクを決定しましたが、それとほぼ同じことを行います。
仮想マシンのMACアドレスの値は、元々16進数ですが、10進数化して、その値をMOD計算します。
利点と考慮事項
このポリシーの利点は、例えば単一の仮想マシンが複数の仮想NICを持っている場合、必ずMACアドレスは別々の値が割り振られますので、1つの仮想マシンであっても、仮想NICごとに異なる物理アダプターを利用出来ると言えます(MACアドレスは基本連番で割り振るので、これに従えば、という前提です)
このポリシーの考慮事項は、IPハッシュと同じく、ハッシュ計算が発生するため、他のポリシーよりはリソース利用上のオーバーヘッドが発生する点にあります。(但しIPハッシュほどではありません)
実際に計算をやってみた(MACハッシュ編)
計算が苦手な私ですが、vSphereの知識を深めるためにいろいろ調べてみました。
vSphereの仮想マシンのMACアドレスには、ベンダーコードとして00:50:56が先頭に入りますね。
仮想 NIC の静的 MAC アドレスを設定する (219) – VMware KB
今回は2つの仮想マシンが稼働している環境を下図のように設定したとします。
一旦MACアドレスを計算機で16進数から10進数へ変換します。Windows標準の計算機を”プログラマー”用計算機に変更し、入力値として005056111111と入力した結果、DECという行に10進数変換後の値が表示されました。(345,041,342,737という値がそれです)
これを、MOD4で計算します(この4は物理アダプターの数が4つなので4です)
Modulo計算には次のサイトを利用しました。https://www.miniwebtool.com/modulo-calculator/
以下のサイトで計算をした所、1という値が出ましたのでこの仮想マシンは現状の環境ではvmnic1を利用します。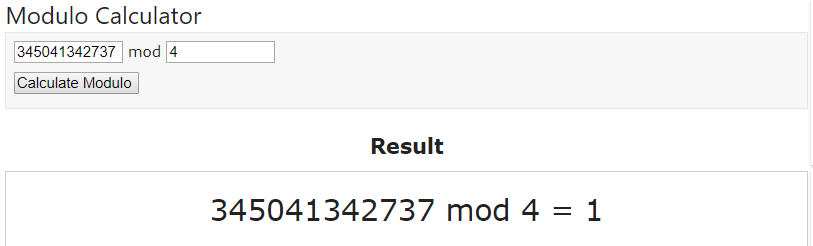
2台目の仮想マシンについても同様の手法で計算します。
まとめ
いかがでしたでしょうか。私もこの記事の執筆を通じて細かな計算メカニズムを掴むことが出来ました。
またチーミングについては5つのポリシーがありますが、環境に応じて最適なものは異なります。本番環境で動作前にテストを行う事を強くおすすめ致します。
最後に改めてこの記事寄稿のきっかけを作ってくれたvmiss氏に感謝を述べたいと思います。本記事以外にもvmiss氏の記事は大変参考になるものが多いため、是非ご興味がある方は以下のリンクから足を運ばれてはいかがでしょうか?:)
I highly recommend vmiss’s blog has a lot of nice articles, thanks again your support for my article, @vmiss.
Please click this icon to jump her blog.![]()
コメント